읽는 시간: 2분
앱스플라이어와 네이버, 오디언스 연동 발표로 디지털 마케팅 역량 강화



앱스플라이어는 매일 수백 만 건의 앱 인스톨을 처리합니다. 각 인스톨 정보에는 앱 설치 발생 시점(time stamp)부터 앱 설치가 발생한 디바이스의 센서 신호까지 수많은 데이터 측정 포인트가 담겨있습니다. 이 모든 데이터들을 모아 보면 각 인스톨에 대한 유용한 정보를 알 수 있고, 각 인스톨의 품질 – 즉, 프로드인지 아닌지 – 도 파악할 수 있습니다.
안타깝게도, 모바일 생태계를 떠도는 많은 인스톨들이 허위 어트리뷰션을 주장해 마케팅 비용을 뺏아가는 프로드(fraud)입니다.
이제 프로드 방지 보안은 모바일 비즈니스에서 어트리뷰션 측정에 버금가는 필수 요소입니다.
프로드 방지 기술이 발전하면서 프로드 수법도 진화하고 있습니다. 사기꾼들은 새로운 기술이 도입될 때마다 새로운 빈틈을 파악하고 악용합니다. 이에 대응해 프로드를 적발하는 기술이 또 더 빨리 발전해야 합니다.
디바이스 팜이나 봇이 만들어내는 허위 인스톨이나, 실제 인스톨의 어트리뷰션을 훔치는 인스톨 하이재킹같은 인스톨 프로드는 인스톨 인증 방식, 즉, 프로드 클러스터 패턴을 이용하여 감지할 수 있습니다. 그러나 표본이 적은 프로드 케이스는 감시망에서 벗어나기도 합니다. 사기꾼들이 트래픽이 적은 사이트로 샘플이 적은 점을 악용해 프로드를 저지를 수 있습니다.
각 인스톨마다 프로드인지 아닌지 감별하는 작업은 고난이도 기술이 필요합니다. 프로드 분류 작업이 문제가 아니라 분류 로직을 정확히 짜야합니다. 그래서 앱스플라이어는 정확한 프로드 분류기(classifier)를 개발하기 위해 연구했습니다.
프로드 분류기에 대한 다음과 같은 목표를 세웠습니다.
위와 같은 목표로 프로드 분류기를 연구하던 중 베이지안 네트워크(Bayesian network)를 활용하게 되었습니다.
베이지안 네트워크는 기본적으로 아래와 같은 방향성 비순환 그래프(DAG, Directed Acyclic Graph)를 통하여 변수(variable) 사이의 의존도를 측정하는 확률 모델입니다.
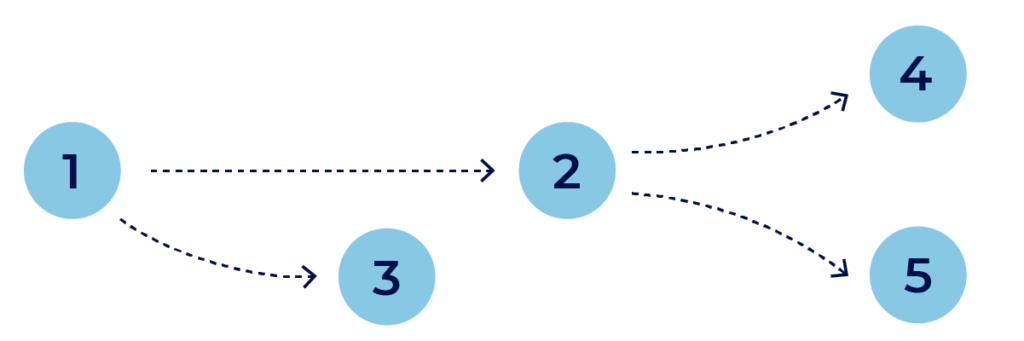
베이지안 네트워크 분석 방식은 프로드를 규정하는 인스톨의 특정 매개 변수 모음을 발견할 확률을 계산합니다. 서로 다른 변수 간 의존성을 모델링하여 어떤 변수 사이가 서로 의존성이 있고 어떤 변수 사이가 그렇지 않은지를 파악합니다.
베이지안 네트워크는 발생한 이벤트를 분석하여 이미 알려진 발생 요인 후보의 확률을 예측할 때 주로 사용됩니다.
예를 들어, 베이지안 네트워크는 병과 병 증상 사이의 확률적 관계를 나타냅니다. 특정 증상이 나타나면, 베이지안 네트워크를 이용하여 각 질병의 발병 확률을 계산합니다.
특정 기준을 적용하여, 카이 제곱 검정(Chi-square test) 방식으로 변수들 사이의 조건적 의존성을 테스트합니다. 모든 변수들이 서로에게 의존적이라고 가정하면 프로드 가능성을 계산하기 쉽지만 실제로는 두 개 이상의 변수들 사이에 의존성이 있을 수도 있고 없을 수도 있기 때문에 프로드 검증이 단순하지 않습니다.
예를 들어, 변수가 디바이스 모델, OS 버전이라고 합시다. 디바이스 모델과 OS 종류 및 버전 사이에는 의존성이 있습니다. 아이폰의 OS는 iOS 입니다. ‘아이폰 11 – 안드로이드’ 조합은 프로드입니다. 또, ‘아이폰 최신형 모델 – iOS 구 버전’도 프로드일 가능성이 높습니다. 그러나 이런 변수 조합 케이스를 수작업으로 일일이 작성하기는 어렵고 규모 있게 만들기에는 한계가 있습니다.
베이지안 네트워크는 특히 여러 매개변수 조합을 검증할 때 도움이 됩니다. 매개 변수를 한 쌍씩 조사하면 프로드 여부를 판단하기 쉽지만 두 개 이상의 변수들 사이 의존성을 파악하고 프로드를 가려내기란 어렵습니다.
또 다른 예를 들어보겠습니다. 50개의 변수가 있습니다. 각 변수는 10개의 옵션이 있습니다. 그러면 총 10의 50제곱만큼 가능한 조합이 나옵니다.
모든 변수가 서로에게 의존성이 있으면, 500가지의 옵션만 학습하면 됩니다. 계산하기 쉽죠? 그런데 모든 변수들이 다 의존성이 있는 것은 아닙니다.
프로드 확률을 정확히 계산하기 위해, 우선 어떤 변수가 독립적이고 어떤 변수끼리 의존성이 있는지를 알아야 합니다. 이는 베이지안 네트워크로 확인할 수 있습니다. 많은 다양한 변수들 사이의 연관성을 밝혀 프로드 확률을 정확히 계산할 수 있습니다.
앱스플라이어는 베이지안 네트워크로 인스톨 하나마다 프로드 확률을 계산합니다. 이 확률은 프로드 확정 오류를 피하기 위해 정해진 앱스플라이어의 엄격한 기준을 통과할만큼 의미있는 확률이어야 합니다.
이렇게 혁신적인 베이지안 분석 모델은 이미 모바일 생태계에서 사용되고 있으며, 앱스플라이어는 하루에 백 만여 건의 인스톨 프로드를 감지하며 이 중 50%가 베이지안 분석 모델이 없었으면 찾지 못했던 프로드 건입니다. 베이지안 분석 기술로 앱스플라이어 고객들은 수십억원을 구할 수 있습니다.
앱스플라이어는 베이지안 네트워크를 비롯하여 프로드를 감지하는 새로운 기능과 방식을 지속적으로 도입해, 보안 기술을 강화하고 현재와 미래의 프로드 공격에 대응할 역량을 강화하고 있습니다. 지금도 앱스플라이어는 모바일 광고 프로드와의 싸움에서 선전하고 있습니다.


